目次
関連研究を探してネット上を徘徊していると
思いついたアイデアなどは既存のものがオオイノダナァーっと
関心してしまいます。
http://sary.sourceforge.net/
http://cl.naist.jp/
http://www.kusastro.kyoto-u.ac.jp/~baba/wais/other-system.html#free_jp
http://namazu.org/~satoru/unimag/9/
http://pitecan.com/
http://sary.sourceforge.net/docs/suffix-array.html
http://nais.to/~yto/tools/sufary/
http://namazu.org/~satoru/unimag/6/
Suffix Array
結論
Suffix Arrayはとても大きい辞書データ
単語を分解して漏れのない検索ができる
作成アルゴリズム
"真夏のコンサート"という単語があるとする
|
|
これを以下のように分解する
|
↓
真夏のコンサート、夏のコンサート
、のコンサート、コンサート、
ンサート、サート、−ト、ト
|
|
辞書順にソート
|
↓
のコンサート
コンサート
サート
ト
−ト
...
Suffix Ayyay
のコンサート
コンサート
サート
ト
−ト
...
が"真夏のコンサート"のSuffix Arrayです
気がついたこと
単語が特定できれば
真
真夏
真夏の
真夏のコンサート
の検索データーとして不要なことが理解できるだろう
TRIE
以前紹介した
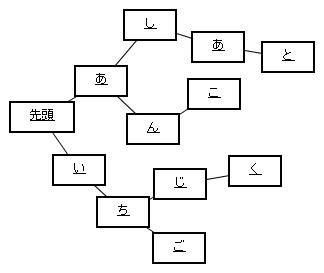 上の構造の名前はTRIEというそうです。
上の構造の名前はTRIEというそうです。
結論
とてもメモリーを食う
一定の速度で検索できる
(もちろん単語が増えると遅くなる、工夫すればたいしたことはなくなる)
ストレージについて
N−Gramを使うと、必然的に
辞書データは大きくなってしまう。
テキストが増えると、必ずメモリーに乗らない量に
陥る。
私の推論では良く使う部分は辞書を圧縮してしまえば
メモリ-にのる。
ZIP圧縮をかけると元テキストの10倍程度のデータに
収まることに注目したい。
(
ただし、zip圧縮はノードごとに
圧縮して連結したものではないのだが
)
今週はは ストレージへの退避する部分と
メモリーに載せる部分を作成考察することにしよう。
そして、次は連想検索部分のインディックスのアイデアを絞って
作成して
文献やpaper等を調べて
最後に 私の卒論の目的である
使用者の探したい文書を推測して、検索を効率化する
まで 、いく っと
できるのだろうか?ぜんぜん分らないことだらけだ
あと、文書共有のための分散技術とか
できるか?